
Issue de Trino, le moteur open source de requêtes SQL distribué, Starburst est une plateforme data/IA conçue pour traiter des requêtes interactives sur plusieurs réservoirs hétérogènes.
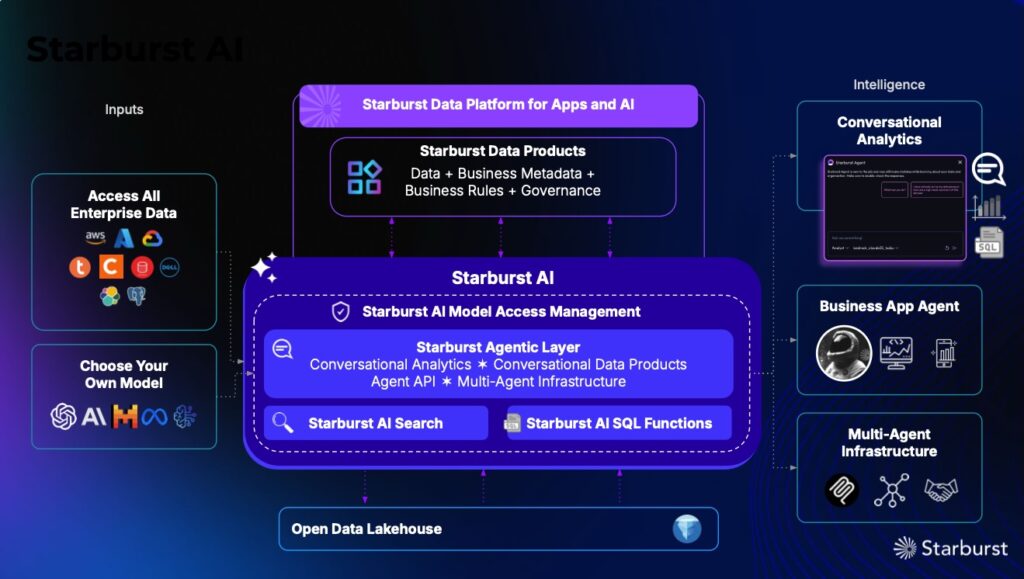
Accélérer l’accès au datalake ne suffit plus. A l’ère des agents IA, toute plateforme de données doit devenir un socle unifié et gouverné de fédération d’indices d’aide à la décision, avec recherche vectorielle et métadonnées contextuelles à la clé. Starburst se distingue par ses connecteurs incluant ElasticSearch, Exadata (Oracle), MongoDB et Teradata.

Les enjeux RSE et le green IT ne sont pas oubliés, puisque le découplage des calculs du stockage devrait contribuer à réduire l’empreinte carbone des infrastructures soutenant les projets big data-IA d’entreprises et de collectivités.

« Il faut penser à Starburst comme à une passerelle de données, recommande Pascal Gasp, Senior Solutions Architect. Son principe permet aux ingénieurs de dissocier le calcul des données, tout en simplifiant la fourniture des informations nécessaires aux métiers. »
Selon lui, de nombreux clients s’inscrivent dans une migration move-to-cloud internationale. Cependant, ils notent que certaines de leurs données ne peuvent pas être hébergées sur un cloud, ou bien portées d’un cloud vers un autre. « Starburst peut être exécuté sur une infrastructure interne, par exemple pour identifier de possibles fraudes à partir d’un cluster dédié, » tranche-t-il.
Des clients grands comptes
Parmi les clients français de Starburst, citons de grandes banques comme BNP Paribas ou le Crédit Mutuel Arkéa, l’opérateur Orange Wholesale, ou encore le logisticien Geodis. La capacité de virtualisation des données du data lakehouse de Starburst apporte à une banque l’agilité et l’évolutivité nécessaires au service informatique pour intégrer de façon sécurisée de nouvelles sources de données, afin d’accélérer la prise de décision ou d’optimiser les résultats financiers des équipes

« Nous répondons aux besoins d’innovation, de souveraineté et de recherche d’économies, en minimisant les copies et en offrant un meilleur contrôle des données, » assure Nathan Vega, Senior Director of Product de l’éditeur.
Lorsque de gros dossiers techniques ou juridiques doivent être compilés rapidement, l’usage du RAG sur des métadonnées bibliographiques permet d’interagir en langage naturel et en mode conversationnel avec des collections, pour en extraire les quelques pages de documents les plus pertinentes au cas du jour.
Les données les plus sensibles pourront être automatiquement classifiées, tandis que des indicateurs de performances réunis dans une table seront confiés à un modèle LLM pour structurer de prochains rendez-vous client. En somme, la plateforme de données entend devenir un outil de collaboration augmenté par l’IA apte à relever la productivité des équipes et à améliorer la qualité des échanges clients.
Version communautaire ou avec support 24×7
La solution communautaire Open Source Trino (ex‑PrestoSQL) est distribuée sous licence Apache 2.0, gouvernée par la Trino Software Foundation, dont Starburst est l’un des principaux contributeurs avec des mainteneurs et fondateurs toujours activement impliqués.
Pour bénéficier d’un support 24×7 par l’équipe Trino/Starburst, il faut se tourner vers Starburst Enterprise – la version auto-hébergée – ou Starburst Galaxy, la solution SaaS. Elles apportent plusieurs options de sécurité, des statistiques, l’autoscaling et la haute disponibilité, ainsi que des connecteurs pour Oracle, Teradata, Snowflake, Synapse, DB2, Netezza, Salesforce, Splunk et Stargate. Warp Speed accélère les requêtes sur le datalake, et procure une indexation intelligente et un cache multi-niveaux. Enfin, Stargate permet de traverser plusieurs régions et clouds en respectant la souveraineté et les contrôles d’accès. Pour sa part, la couche sémantique gouvernée Data Products propose de publier et de consommer des jeux de données prêts à l’emploi.
Le modèle économique par abonnements
Starburst Galaxy (SaaS) est facturé à l’usage sous forme de crédits, avec un suivi détaillé de la consommation et une facturation directe ou indirecte au travers des places de marché cloud. Il faut compter 0,50 $/crédit en version Pro, 0,75 $/crédit en version Enterprise et 1,00 $/crédit en version Mission‑Critical .
Pour sa part, Starburst Enterprise (version auto-hébergée) est disponible sur devis, l’abonnement dépendant du dimensionnement suit alors une tarification par capacité (vCPU).




